Book Tracking
2011-10-27
Those of you who follow me on Twitter will know that I recently closed my Shelfari account. The reason for this is their restriction against exporting my library: some new policy in the last year required your profile to be at least 90% complete for your library to be exportable. This didn't use to be the case, and it understandably led to a lot of complaints (but which the Shelfari staff never justified). Getting up to that percentage required me to join a few groups (which I didn't want to) and add "friends" (which I don't have... kidding! *sob*). I joined a few generic groups, but really didn't want to contact other people to be friends, and eventually gave up on that process. The upshot of this is that I closed my account entirely.
I've therefore set up a new account at Goodreads. It has worked well for me so far; I particularly like how the tag system is done through a "hovering" dialog box, so I can very quickly move from one book to the next. In Shelfari this was through a model dialog, which required more clicks to do the same thing. In general Goodreads do a better job at user interface. There is a lot less AJAX crud, which makes the page load faster. I'm also keeping an eye on the recommendation system, although I don't have too high hopes for it. I suspect the system is much more useful for fiction than non-fiction, where people read largely similar books; with non-fiction, it's boring to read about the exact same topic over and over again.
Anyway, in the process of switching to Goodreads I had to export my library from Shelfari. Recall that I had given up on making Shelfari allow me to export my list. Instead, I loaded up their list of my books, then saved the HTML. I then wrote a quick script which extracted the authors and titles of books. Ah, the advantages of being a programmer... Here I hit a snag: Goodreads allows users to import books, but only by ISBN. Shefari, in its exported CSV file, contains those, but not on it's normal display page. Luckily, I had a backup file of my library, so I had ISBNs for the majority of my books, but not all of them. For the rest, I used the Library of Congress' Search via URL service, which would return detailed book information given a title and an author... which I have! Putting everything together took about an hour, manually verifying that the books were correct a little longer, but at the end of that I had completely moved my library with minimal loss of information. The other upshot is that I cleaned up my list a little, removing books that I'm no longer interested in.
To make sure that this wouldn't happen again, I checked the file that Goodreads would export. It had more information than Shefari, which was nice. What caught my eye was that, in addition to the ratings I gave my books, the exported spreadsheet also contained other reader's average ratings. Which allowed me to make the following plot:
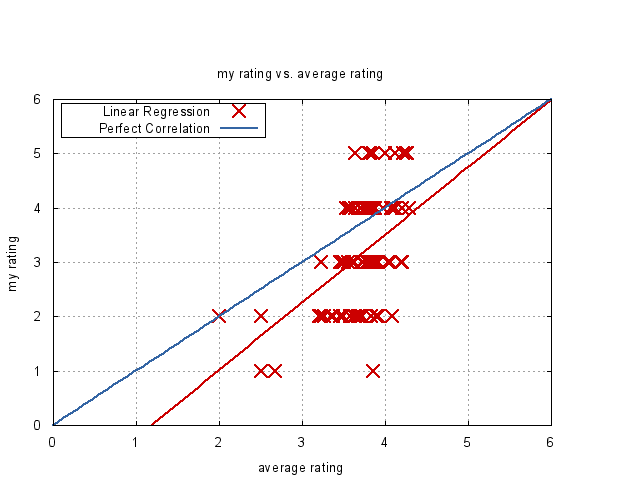
The x-axis is the average rating of other people of any particular book on Goodreads, while on the y-axis is my own rating. The red crosses are the books on this scale, while the red line is a linear regression over these points. The blue line is y=x; that is, what the regression should look like if my ratings were exactly in line with the average reader. As you can see, I have a slightly lower opinion of books in general, especially on the lower end of the scale. Qualitatively, my tastes agree with the average reader, but the discrete ratings on my side makes it hard to give a good regression.
PS. A book I'm reading that is not listed on my shelf is Donald Knuth's The TeXbook. One might expect a book about a pseudo-programming language for typesetting to be dry, but Knuth makes it pretty interesting.